

Recently, I posted on LinkedIn about how the average word count in ChatGPT query fan-outs has roughly doubled from October 2025 to January 2026. That post clearly resonated. So in this article, we're going to dig deeper into the data, looking at country-specific trends and exploring what this shift means for anyone working on AI search visibility.
TL;DR
We analyzed 20 million ChatGPT fanout queries and can confirm that the average word count per query fan-out globally has roughly doubled.
It rose from ~6 words in October to ~12 words by January 2026, with a peak of ~16 words around calendar week 49.
This doubling trend is uniform across countries and languages, from English to Thai.
However, the number of QFOs per prompt has stayed roughly constant since the beginning of 2026, meaning ChatGPT is making each individual query more precise rather than simply issuing more queries.
The implications for GEO/SEO, content strategy, and AI search visibility are significant. As QFOs get longer and more specific, the sources that get retrieved, and ultimately cited, will change.
What is a query fan-out?
Before we get into the data, let's make sure we're on the same page. When a user sends a prompt to ChatGPT, the system doesn't just pass that prompt straight to a search engine. Instead, it splits the user's intent into multiple search queries. These are query fan-outs (QFOs). Each QFO is designed to retrieve a specific piece of information that, when combined, allows ChatGPT to construct a comprehensive answer.
For example, a user prompt like "What's the best laptop for video editing under $1,500?" might generate QFOs such as:
"best laptops video editing 2025"
"laptops under 1500 high performance GPU"
"video editing laptop reviews benchmarks comparison"
The structure, length, and number of these QFOs directly determine which sources ChatGPT retrieves and, ultimately, which websites get cited in its responses.
Country-level data confirms a uniform global trend
Here is how the QFO trend looks on a global level. We observe that QFOs have roughly doubled in word count from October 2025 to the end of January 2026.
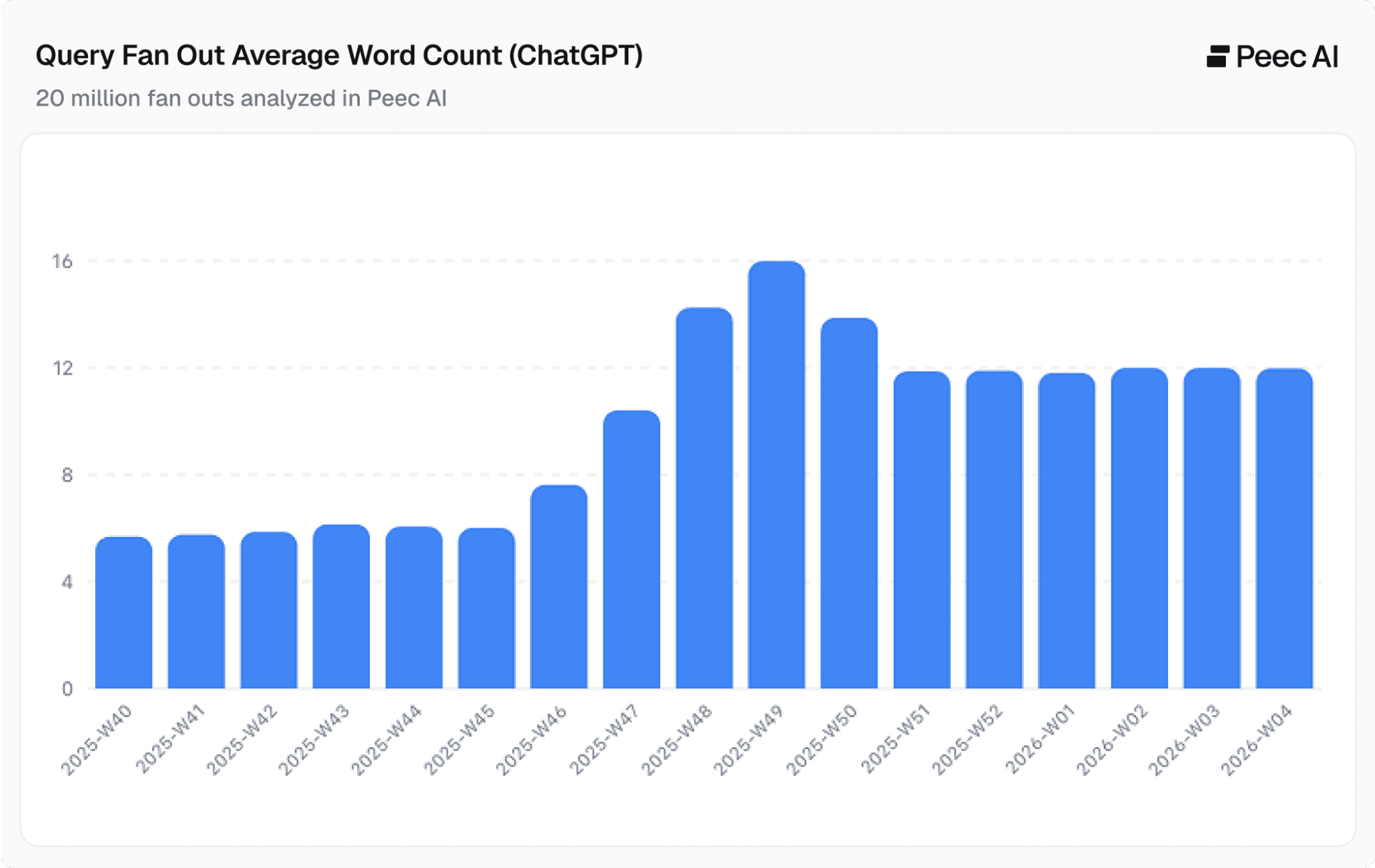
Note: All data in this article comes from Peec AI, where we've analyzed over 20 million query fan-outs (QFOs) generated by ChatGPT between October 2025 and January 2026.
Let's now look at five representative countries: Germany, the United Kingdom, Singapore, Thailand, and the United States. This gives us a good mix of languages with different grammars, alphabets, and average word lengths.
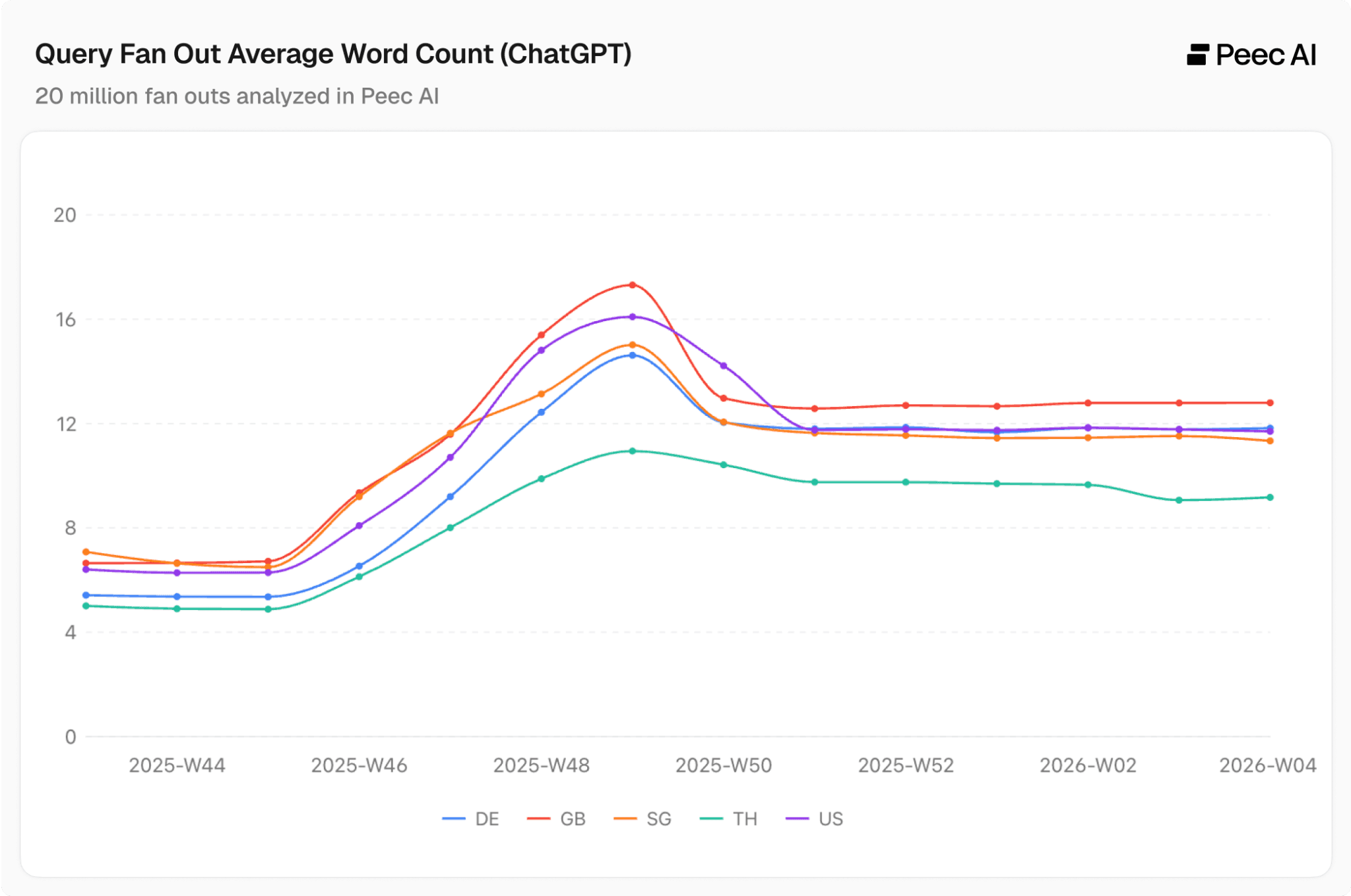
Country Codes:
DE = Germany
GB = United Kingdom
SG = Singapore
TH = Thailand
US = United States
Across all countries, QFO word count roughly doubled in late 2025, having briefly spiked in November, and has remained stable since the beginning of 2026.
We see minor deviations due to language-specific reasons. For example, German compound words often pack more meaning per word than English, while Thai has its own structural characteristics.
The finding that will be a constant theme throughout this article: the trendline of how ChatGPT query fan-outs change over time is virtually identical across all countries and languages.
This uniformity isn’t surprising. When OpenAI updates how ChatGPT works those changes apply universally. There's no region-specific tweaking happening.
This is completely different from Google organic search, where ranking algorithms, search features, and SERP layouts often vary by locale. It's yet another reminder that AI search behaves fundamentally differently from traditional search.
Confirming the trend with character count
Character count confirms the uniform trend across countries. When we measure by characters instead of words, the trend is nearly identical across all languages, meaning ChatGPT is genuinely increasing the complexity and specificity of its QFOs.
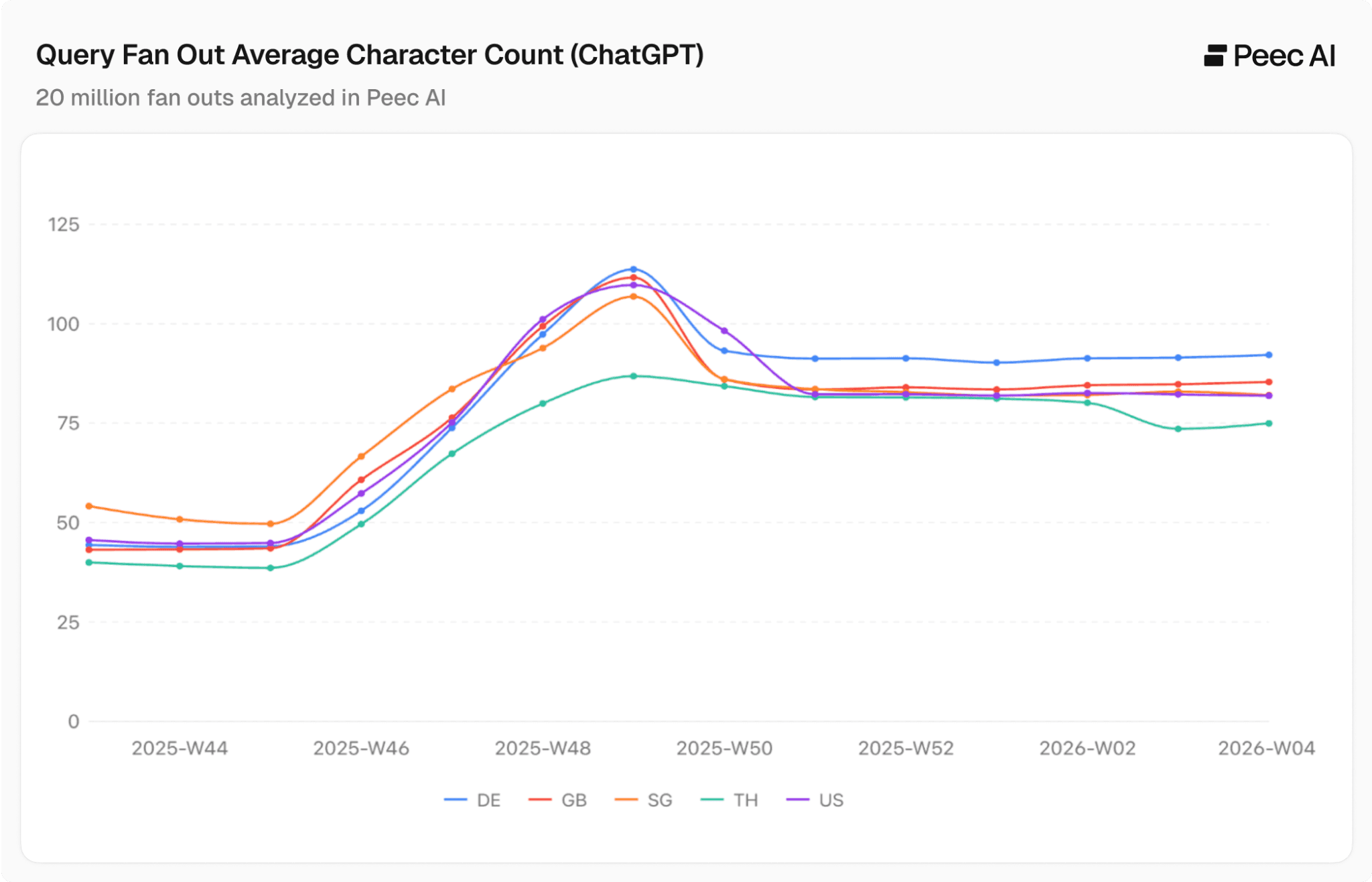
The increase holds whether you measure by words or by characters, across all languages in our dataset.
How many query fan-outs does ChatGPT use per prompt?
Here's where things get interesting. While we've seen an almost uniform doubling of word count in QFOs, the same is not true for the average number of query fan-outs per conversation.
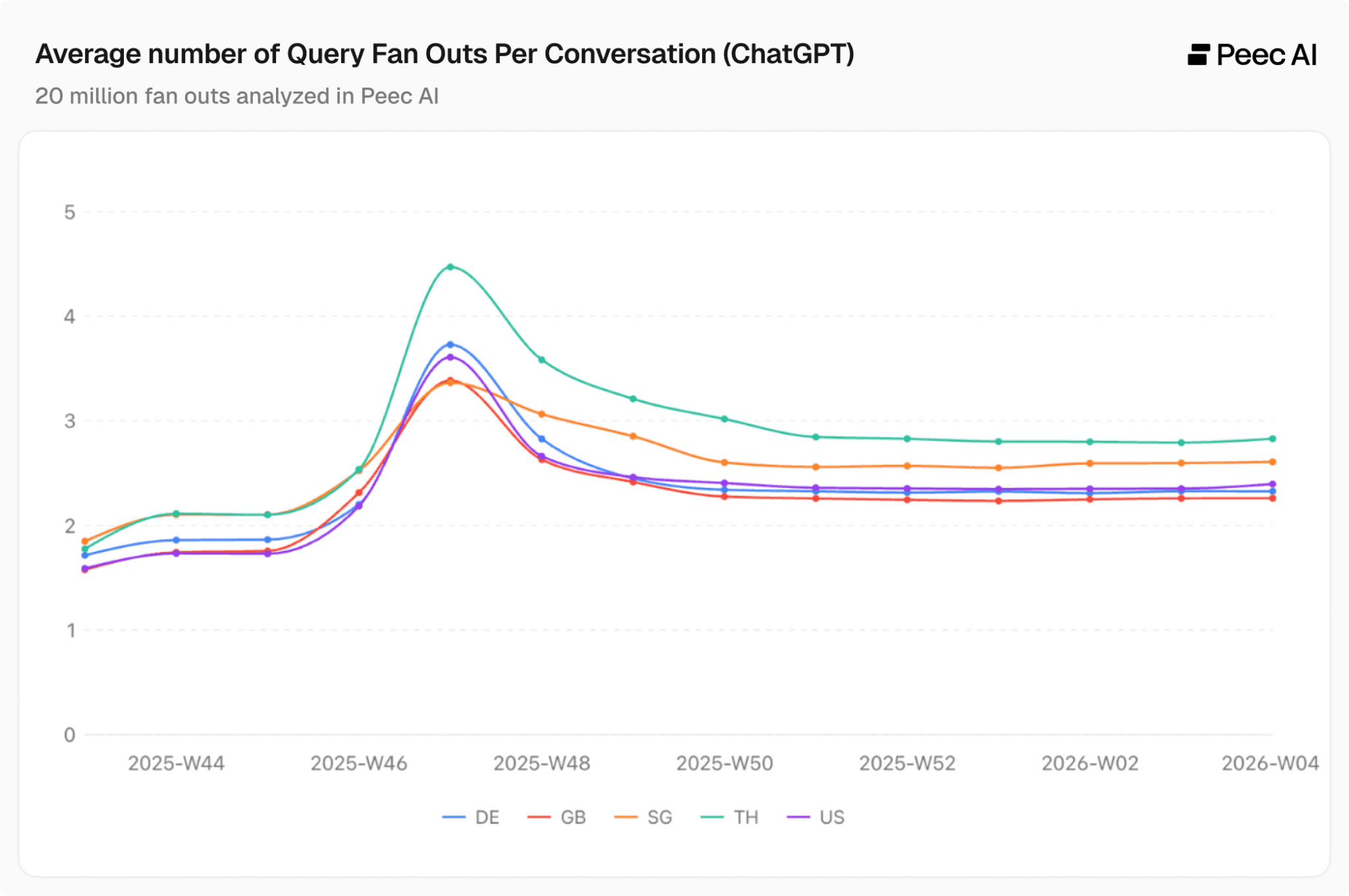
In October/November 2025, we did see first a slight dip, then a more pronounced spike, but this appears to be temporary when compared to the sustained increase in average word count.
Excluding that anomaly: in the first week of October 2025, the range for these 5 countries was 2.4 to 2.8 QFOs per prompt; in the final week of January 2026, the range was 2.3 to 2.8. Almost identical.
What does this tell us? It strongly suggests that the primary motivation is to increase the precision of each individual query rather than simply run more searches overall. The goal is better results per query, not more queries overall. ChatGPT is crafting each individual search to be more targeted and specific.
So why is ChatGPT doing this?
We can't know OpenAI's exact reasoning, but the data points to two compelling theories.
Better search precision
Modern retrieval systems, like the one powering ChatGPT's search, rely on vector embeddings and cross-encoder models to compare query meaning against a vast index of content. In simpler terms, these systems analyze what a query actually means and try to find content that matches that intent, not just content with the same keywords.
The more context a query contains, the more precisely these models can match it to truly relevant content.
A short query like "best laptop" is ambiguous. It could relate to dozens of intents. A longer query like "best laptop for professional video editing under 1500 dollars 2025 reviews" gives the system a much richer signal to work with. The result is more relevant retrieval, better re-ranking, and ultimately higher-quality answers.
As these ranking and retrieval systems become more sophisticated, the queries need to become more detailed. The QFO is, in effect, being optimized for the retrieval stack.
The AI content saturation problem
The internet is increasingly saturated with AI-generated content. As the volume of published content explodes, finding genuinely relevant, high-quality sources becomes harder for large language models (LLMs) during web search retrieval. By using longer, more specific QFOs, ChatGPT can better differentiate between content in two ways:
Longer queries produce more long-tail, and therefore more specific, web search results.
When ChatGPT compares the query fan-out to the retrieved webpages via vector search, there is more context to work with.
These two theories work together. As search technology advances and the web becomes increasingly saturated with AI-generated content, longer and more specific queries become necessary to maintain answer quality.
Key takeaways for AI visibility teams
As query fan-outs get longer and more complex, this naturally changes which sources are retrieved for each prompt. Tracking your query fan-outs over time helps you understand both what ChatGPT is searching for and which sources get retrieved.
The content that gets cited in AI search will be the content that matches the increasingly specific queries ChatGPT generates behind the scenes. Content specificity matters more than ever. Broad, generic pages will struggle to match, while detailed content that directly addresses specific user intents will have an advantage in retrieval.
The other important takeaway is that ChatGPT's algorithm changes tend to apply universally across all countries. The uniformity of this trend means it's not a localized experiment but a global, architectural shift in how ChatGPT searches the web.
For AI visibility teams, analyzing global trends may be more useful than trying to make sense of apparent local changes.
Stay tuned as the Peec AI research team will have much more to share on query fan-outs in the coming weeks.
Data: Peec AI, 20 million+ ChatGPT query fan-outs, October 2025 to January 2026.





